What is the difference between percentile and percentage?
A percentage is a ratio expressed out of 100 (e.g. 75%). A percentile is a position in a ranked dataset. Scoring 75% on a test means you got 75 of 100 questions right. Being at the 75th percentile means you scored higher than 75% of all test takers — you could achieve this by scoring 60% if most others scored lower.
Why does this differ from other percentile calculators?
There are several methods for computing percentiles (exclusive, inclusive, nearest-rank, etc.). This calculator uses the linear interpolation / inclusive method (Excel PERCENTILE.INC, Python numpy default). Other methods may produce slightly different results, especially for small datasets.
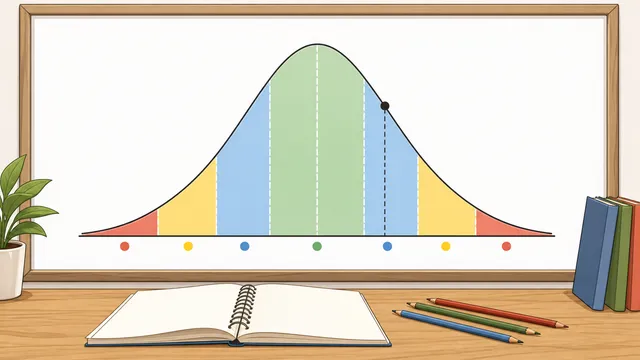
What is the percentile in a normal distribution?
For a normal distribution, percentiles correspond to z-scores. The 50th percentile is the mean (z=0), the 84th percentile is one standard deviation above the mean (z=1), and the 97.7th percentile is two standard deviations above (z=2). Use the normal distribution calculator to find exact percentiles for a given mean and standard deviation.
What does a percentile calculator do?
A percentile calculator sorts your dataset and finds the value at a requested percentile, such as P25, P50, P90, or P95. A stronger percentile calculator also helps with the reverse question: given a value, what percentile rank does that value have within the dataset?
What is the difference between percentile value and percentile rank?
A percentile value answers, “What number is at this percentile?” For example, P90 might be 720. Percentile rank answers, “Where does this specific value sit?” For example, a score of 720 might have a 90th percentile rank. The first returns a cutoff value; the second returns a relative position.
Should I use linear interpolation or nearest rank?
Use linear interpolation when you want smooth, spreadsheet-style percentile estimates for general analysis. Use nearest rank when the percentile result must be one of the observed data values. The difference is most noticeable in small datasets and at tail cutoffs such as P90, P95, and P99.
Why can a percentile be a value that is not in my dataset?
Interpolation estimates a point between two neighboring sorted values when the percentile location is fractional. That is why P75 for a small dataset might be 56.5 even when no entered value is exactly 56.5. Nearest rank avoids this by choosing an observed value, but it produces less smooth cutoffs.
How many values do I need for a meaningful percentile?
A percentile can be calculated from a very small dataset, but small-sample percentiles are unstable. With only a few values, adding or removing one observation can move P90 or P95 dramatically. Use small datasets for learning or quick summaries, and use larger samples before drawing strong conclusions about tails or benchmarks.
What are P25, P50, P75, P90, and P95 used for?
P25, P50, and P75 are the lower quartile, median, and upper quartile. They describe the middle of a distribution and are useful for salaries, prices, and test scores. P90 and P95 are upper-tail cutoffs often used for performance benchmarks, latency targets, high-end compensation, and outlier screening.
Do I need to sort my numbers before using the calculator?
No. The calculator parses your comma-, space-, or line-separated values, sorts the numeric entries internally, and then calculates the percentile or percentile rank from the ordered dataset. The sorted-data display is included so you can check the calculation path.
Why does the calculator reject text mixed into the dataset?
A percentile calculation depends on the exact set of values being ranked. If the calculator silently dropped a token such as "late", "30ms", or a unit label, the result could look precise while using a smaller dataset than you intended. The warning asks you to remove or correct invalid entries so the percentile value, percentile rank, and every-fifth-percentile table all use the same audited list.
Can this calculator handle grouped frequency data?
This calculator is designed for raw numeric lists. Grouped frequency data usually needs a different workflow using cumulative frequencies and interpolation within bins. If you only have bins instead of raw values, do not paste bin labels as though they were individual observations.